Control de versiones de Git
El control de versiones es un sistema que guarda los cambios en el tiempo de uno o varios archivos.

¡Hola! Mi nombre es Marco Madera soy programador web frontend por afición y entusiasta de las tecnologías web que cada día me gustan más: JavaScript, Node.js, React, etc.
En mis inicios programando siempre escuchaba algo sobre el control de versiones, era algo que veía un poco complicado y donde no me quería meter porque estaba más enfocado en aprender otras cosas. Lo simplificaba como en qué estado se encuentra mi proyecto y usar versión alpha, beta, v1.0.0... Lo que ahora veo como una etiqueta que no se altera. Esto me llevó a realizar cambios sin justificación y a perder mucho trabajo que no guardé.
En algún momento al conocer Git me sentí igual que Flavio y por los recuerdos me dio a escribir sobre Git para no olvidar de que vale la pena saber más de unos comandos.
¿Qué es el control de versiones de Git?
El control de versiones es un sistema que guarda los cambios en el tiempo de uno o varios archivos. Se pueden revertir estos cambios a un estado anterior, lo que significa que si tenemos un problema, podemos comparar los cambios en el tiempo, ver quién modificó algo que pudiera causar el problema y poder cambiar el estado actual a uno donde no se presente el problema.
Git es un sistema de control de versiones que almacena la información como un flujo de snapshots de un sistema de archivos. Cada vez que hay un cambio o se guarda el estado del proyecto, Git toma una imagen de todos los archivos y crea una referencia a ese momento. En un futuro cambio, si un archivo no se modifica Git no vuelve a almacenar el archivo, sino que usa la referencia al momento anterior.
Git contempla tres estados:
modified: Cuando un archivo cambia, pero no se ha enviado a la base de datos local de Git.staged: Cuando se añade un archivo modificado para ser enviado en el siguientecommit.commited: Cuando los datos están almacenados en la base de datos local de Git.
Configuración de git
Para usar Git lo primero que se debe de hacer es instalarlo, se obtiene desde la página de descarga siguiendo los pasos según el sistema operativo que tengas.
Una vez instalado podremos usar en nuestra consola el comando git config --list para ver la configuración de Git. Para modificar los datos para el entorno global usamos git config --global <configuración> <valor>.
Lo esencial a modificar tiene que ser el nombre y el email, que son las configuraciones que usan todos los commits.
git config --global user.name "MarcoMadera"
git config --global user.email "example@email.com"
git config --list
http.sslcainfo=C:/Program Files/Git/mingw64/ssl/certs/ca-bundle.crt
core.autocrlf=true
core.fscache=true
core.symlinks=false
pull.rebase=false
credential.helper=manager
core.editor="C:\Users\marco\AppData\Local\Programs\Microsoft VS Code\Code.exe" --wait
user.name=MarcoMadera
user.email=example@email.comUso básico
El flujo de trabajo en Git sigue el siguiente patrón:
- Haces modificaciones en tu directorio de trabajo controlado.
- Selecciona los cambios a añadir en el estado staged para ser enviados con el siguiente
commit. - Haces un commit, el cual toma todos los archivos en estado staged y almacena la snapshot en la base de datos de Git.
Para tener un directorio nuevo de trabajo controlado, en la terminal se dirige a la ruta del proyecto para inicializar el repositorio con el comando git init. Esto creará el archivo .git en la raíz del proyecto, donde se guardará la información de cada snapshot.
cd repositorios/gitpost/
git init
Initialized empty Git repository in C:/Users/marco/repositorios/gitpost/.git/Para no ir a ciegas comando tras comandos podemos revisar el estado con git status. Nos informará dónde estamos, sobre el estado de los archivos, si se han modificado, agregado o eliminado.
git status
On branch master
Your branch is up-to-date with 'origin/master'.
Untracked files:
(use "git add <file>...". to include in what will be committed)
README
nothing added to commit but untracked files present (use "git add" to track)Para agregar archivos al stage usamos git add <archivo>, git add * o git add . agrega todos los archivos en el stage, git add *.<extensión> agrega los archivos con la extensión especificada y git add /<folder> agrega todos los archivos dentro de la carpeta especificada.
Si nos equivocamos, para eliminar archivos del stage sin borrarlo de nuestro directorio usamos git rm --cached <archivo>. El flag --cached hace que no se elimine de nuestro directorio, si no se agrega se eliminaría también de nuestro directorio de trabajo. Si olvidamos agregar el flag no está todo perdido, podemos recuperar el archivo con git restore <archivo>.
Para Ignorar archivos se crea un archivo .gitignore en la raíz del proyecto. Esto hace que todos los archivos que coincidan dentro de .gitignore no sean tomados en cuenta para ninguna acción con Git. Puedes revisar la colección de archivos de .gitignore para ver ejemplos o usarlos en tus proyectos.
Ya teniendo todo lo que queramos para guardar los archivos usamos git commit. Esto abrirá el editor que definimos en la configuración para poner un mensaje descriptivo o igual lo podemos añadir en la consola con el flag -m. Para añadir archivos que ya habían estado en el stage usamos el flag -am que es la combinación de -a --add y -m --message.
git commit -m "<mensaje descriptivo>"
git commit -am "<mensaje descriptivo>"Mostrar el historial de commits del repositorio usamos git log, el resultado de este es un poco feo, por lo que se puede hacer más bonito con el flag --pretty. git log solo mostrará por defecto el historial por debajo de la rama.
git log
commit ed3946555db4597294bae2014cfe996b88268bef (HEAD -> master, origin/master)
Author: MarcoMadera <example@email.com>
Date: Mon Jul 6 17:09:50 2020 -0500
hola mundo
commit e150e0079854fa6a5996db6ee692fc1377a1f2ff
Author: MarcoMadera <example@email.com>
Date: Mon Jun 29 19:28:42 2020 -0500
hello world
git log --oneline
65b5a12 (HEAD -> master, origin/master) hello world
fd14a30 hola mundo
git log --pretty=format: "%h | %cn | %cr | %s"
65b5a12 | MarcoMadera | 10 minutes ago | hello world
fd14a30 | MarcoMadera | 11 minutes ago | hola mundoPara mostrar las diferencias entre un commit y otro de un archivo lo hacemos con el comando git diff. git diff muestra la diferencia por defecto de lo que has puesto en el stage y lo que vas a hacer commit. Muestra las líneas exactas que fueron añadidas o removidas. El comando puede ser selectivo usando el hash de cada commit a comparar.
Usar git diff no suele ser muy placentero de ver para archivos largos, se puede explorar el uso de git difftool para configurar una herramienta más gráfica para estos casos.
git diff commitA commitB
diff --git a/index.js b/index.js
index 5e1c309..ade1f58 100644
--- a/index.js
+++ b/index.js
@@ -1 +1 @@
-Hello World
+Hola Mundo
git difftool commitA commitB
Hello World | Hola Mundo
~ | ~El modelo de ramas
Se puede decir que Git tiene tres árboles donde se agrupan archivos. HEAD es el indicador del último commit realizado y de la rama actual. Index es el espacio donde se agregan/modifican/eliminan los archivos del antes mencionado stage antes de realizar un commit. Finalmente está el directorio de trabajo manejado como el Working tree
Al realizar el comando git init Git crea una rama por defecto que suele ser master. Esta no es una rama especial, es como cualquier otra con el detalle que es la inicial, la que Git crea por defecto. Nuestro proyecto puede seguir cualquier rama como principal en cualquier punto.
Cuando un commit es creado es mandado al HEAD, la rama actual, donde Git guarda la información de los cambios una única vez, lo demás son referencias con cambios, no se vuelve almacenar nada ya creado. Con esto Git permite crear copias de nuestro proyecto en un estado en formas de referencias y experimentar con ellas todo lo que queramos sin haber otro coste más que los nuevos cambios. Estos grupos de referencias en un estado son llamadas ramas que igual tendrá solamente un identificador propio.
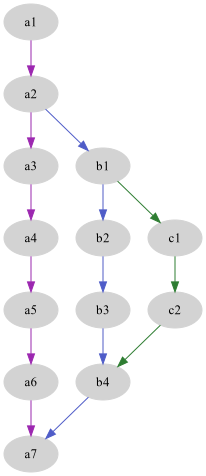
Ahora que tenemos una idea de lo que son las ramas pasemos al manejo de ellas. Para crear una rama usamos git branch <nombre de la rama>, esto creará un indicador llamado HEAD que apuntará a la rama en la que estamos para ubicarnos mejor, en este caso aún seguiríamos en la rama master. Para cambiar de ramas usamos git switch <nombre de la rama> o git checkout <nombre de la rama>, esto moverá el apuntador HEAD a la nueva línea en la que estaremos trabajando.
En algún punto las ramas pueden volver a unirse a la rama principal o a otra rama, como se muestra en la gráfica anterior. Todo lo que tienes que hacer es ir a la rama donde se van a hacer los cambios y usar git merge <nombre de rama>. Git creará una nueva snapshot de los cambios y un nuevo commit de referencia especial porque tendrá dos ancestros directos.
git checkout master
Switched to branch 'master'
git merge <nombre de rama>
Merge made by the 'recursive' strategy.
index.js | 1 +
1 file changed, 1 insertion(+)
create mode 100644 index.jsNo todo es tan bonito siempre. Al momento de unir ramas, si cambias la misma parte del mismo archivo en las dos ramas que se han unido ocurrirá un conflicto, Git no podrá unirlas tan fácil, te indicará dónde está el conflicto y te pedirá que lo arregles.
git merge <nombre de rama>
Auto-merging index.js
CONFLICT (content): Merge conflict in index.js
Automatic merge failed; fix conflicts and then commit the result.Esto de unir ramas se puede volver un caos y nosotros podemos saber el trabajo que conlleva, pero ¿se lo queremos presentar al público así?. Al final lo que la gente ve es el resultado final y si alguien quiere ver como lo hiciste puede que quieras mostrar algo más coherente.
Se puede aplicar a lo que estás leyendo, duro tres días haciendo el artículo porque escojo el tema, investigo un poco, hago el borrador, creo las imágenes si las necesito, escojo los colores y reviso las faltas de ortografía. Lo primero que hice es hacer la gráfica de las ramas, pero si alguien ve el historial puede que no tenga sentido para nada.
El historial de commits es tal y lo que pasó, cambiar este historial sería cambiar el historial de cómo el proyecto fue construido. Los errores son parte de la historia del proyecto y son necesarias incluso para estudiar las soluciones.
El uso de git rebase puede ir en contra de esto porque coloca la base de una rama de un commit a otra rama diferente, pero en algunos casos puede ser útil, simplemente porque tal vez no quieras tener una rama completa para un cambio tan pequeño. Una vez ya acabado el trabajo de unir ambas ramas se puede eliminar la rama porque ahora está apuntando a la rama principal, por lo que ya no sería necesaria. Para eliminar ramas se hace con git branch -d <nombre de rama>.
git checkout <nombre de rama>
git rebase master
Successfully rebased and updated refs/heads/<nombre de rama>.
git checkout master
git merge <nombre de rama>
git branch -d <nombre de rama>
Repositorio Remoto
Todo lo que hemos estado trabajando es sobre el repositorio local de nuestro proyecto. Para que otras personas lo vean y colaboren con él, podemos usar los servicios remotos como GitHub, Bitbucket y GitLab; son servicios que permiten la gestión de proyectos y el seguimiento de trabajo con otros desarrolladores.
Para subir un repositorio local a uno remoto, tendremos que crear un repositorio en algunos de los servicios en el cual obtendremos una url del nuestro proyecto, con la que podremos utilizar git remote add <nombre indentificador> <url>
Otra forma de obtener un repositorio es clonar un repositorio remoto con git clone <url> <nombre>. Con esto ya tendremos en nuestro directorio local una copia con la que podremos contribuir al proyecto o simplemente experimentar con su funcionamiento.
git clone https://github.com/MarcoMadera/Blog.git GitPost
Cloning into 'GitPost'...
remote: Enumerating objects: 64, done.
remote: Counting objects: 100% (64/64), done.
remote: Compressing objects: 100% (45/45), done.
remote: Total 64 (delta 32), reused 45 (delta 17), pack-reused 0
Unpacking objects: 100% (64/64), 74.53 KiB | 19.00 KiB/s, done.Después de usar git clone, si usamos git remote veremos que tendremos origin, este es el nombre para identificar la url que Git le pone por defecto a los proyectos obtenidos por git clone. Esto sucede al igual que al inicializar un proyecto, Git por defecto crea la rama con nombre master. Se puede renombrar el identificador con el comando git remote rename <origin en este caso> <nuevo nombre>
Ahora que tenemos un repositorio remoto, puede que el contenido del remoto sea diferente por cambios de otros colaboradores. En nuestro repositorio local no se verán reflejados esos cambios. Para actualizar nuestro repositorio local podemos usar git pull. Trae los cambios generalmente del servidor al que se clonó y hace un merge automático en nuestro repositorio local. Para indicar otro servicio remoto y rama se usa git pull <remoto> <rama>
Cuando ya hemos hecho commit de los cambios que queremos compartir en nuestro repositorio, para actualizar el repositorio remoto usamos git push <remoto> <rama>, si alguien ya hizo un git push antes, nuestros cambios serán rechazados por lo que siempre es bueno hacer git pull antes.
Comandos de Git adicionales
Si no quieres escribir el comando completo cada vez, puedes fácilmente configurar un alias para cada comando. Los alias en Git nos permiten crear shortcuts, a través de git config --global alias.<atajo> comando.
git config --global alias.<atajo> "<comando>"
git config --global alias.st "status"
git git config --global alias.slog "log --pretty=format:'%h | %cn | %cr | %s'"
Si ya hicimos commit y olvidamos añadir un archivo o enmendar algún cambio podemos hacerlo con el comando git commit --amend. Igualmente si nos equivocamos en la descripción de nuestro commit lo podemos arreglar con el mismo comando si lo invocamos inmediatamente después de haber ocurrido el error.
git commit -m "<mensaje>"
git add <archivo>
git git commit --amend
Git mantiene un log de dónde el HEAD y sus referencias han estado. Lo podemos ver con el comando git reflog y mostrar más al respecto con git show HEAD@{<número o referencia en días>}
git reflog
2673d2d (HEAD -> master, origin/master) HEAD@{0}: merge newbranch: Merge made by the 'recursive' strategy.
4e85459 HEAD@{1}: checkout: moving from master to master
4e85459 HEAD@{2}: commit: hola mundo
8c821a7 HEAD@{3}: checkout: moving from newbranch to master
git show HEAD@{2}
commit ed3946555db4597294bae2014cfe996b88268bef
Author: MarcoMadera <example@email.com>
Date: Mon Jul 6 17:09:50 2020 -0500
hola mundo
diff --git a/index.js b/index.js
index 5e1c309..ade1f58 100644
--- a/index.js
+++ b/index.js
@@ -1 +1 @@
-Hello World
+Hola Mundo
Para crear una rama y cambiar directamente se usa el comando git checkout -b <nombre de rama> o git switch -c <nombre de rama>. Ahora si quieres volver a la rama anterior se puede usar git switch -.
Para cambiar el nombre de una rama se usa git branch --move <rama> <nuevo nombre>. Para enviar los cambios al repositorio remoto git push --set-upstream <remoto> <nuevo nombre>. Para eliminar la rama anterior del repositorio remoto utilizamos git push origin -d <rama>.
Cuando estamos trabajando, pero queremos cambiar de rama y no hacer un commit de un trabajo incompleto, usamos git stash. Guarda los commits en un estado diferente para poder recuperarlo después con git stash apply.
Git tiene una interfaz gráfica integrada que podemos utilizar con el comando gitk para ver el historial y git-gui donde puedes preparar los commits y experimentar lo visto.
Conclusión
Git nos proporciona una manera elegante de hacer el seguimiento de versiones, nos permite hacer un resguardo y hacer posible la colaboración entre varias personas teniendo espacios de trabajo separados como el local y el remoto. Git también se puede implementar en interfaces gráficas y tiene muchos comandos que no se han tocado en este artículo a fondo, por lo que te invito a investigar más sobre el tema.




