Números Pseudo Aleatorios
Los números pseudo-aleatorios son creados a partir de algoritmos matemáticos, por lo que no se puede decir que son realmente aleatorios.

¡Hola! Mi nombre es Marco Madera soy programador web frontend por afición y entusiasta de las tecnologías web que cada día me gustan más: JavaScript, Node.js, React, etc.
Esta entrada es posible gracias a la aleatoriedad de Math.random() de JavaScript. Surge tras programar el paquete de node random-messages-names el cual como su nombre lo dice retorna mensajes y nombres aleatorios. Tiene 1000 apellidos y 2788 nombres diferentes. Al estar probando me di cuenta de que había veces que ocurrían rachas seguidas de nombres repetidos. Tres o cuatro veces el mismo nombre. Por eso es que me dio por comprobar la aleatoriedad de Math.Random() a través de unas pruebas estadísticas.
Primero hay que saber qué es Math.Random(), la definición de la especificación estándar del lenguaje, ECMAScript 2015 dice:
Devuelve un número con signo positivo. Mayor o igual que 0 pero menor que 1. Elegido aleatoriamente o pseudo aleatoriamente con una distribución aproximadamente uniforme en ese rango. Utilizando un algoritmo o estrategia dependiente de la implementación. Esta función no toma argumentos. Cada función Math.random creada para ambientes de código distintos debe producir una secuencia distinta de valores a partir de llamadas sucesivas.
Dato importante que sacamos de esta definición es que ECMAScript no provee el algoritmo ni la forma de implementarlo. Depende del ambiente que utilizamos, en mi caso, utilizo NodeJs y Chrome. Ambos utilizan el motor V8 para correr JavaScript. Por otro lado Firefox utiliza SpiderMonkey y Safari usa Nitro. Aunque los tres usen el algoritmo xorshift128 +, mis resultados valdrán solo para V8 porque el motor se encarga de escoger la semilla que genera los números.
¿Qué son los números pseudo-aleatorios?
Los números pseudo-aleatorios son creados a partir de algoritmos matemáticos. No se puede decir que son realmente aleatorios, por eso el pseudo. Algunos algoritmos hacen muy bien el trabajo de simular las propiedades de los números aleatorios. Otros caen en el bucle de repetirse infinitamente.
Para que una secuencia de números sea aleatoria, es necesario que tengan una distribución uniforme y que no tengan correlación. Deben de tener la misma probabilidad de ser elegidos y que la elección de uno no dependa del otro.
Distribución uniforme
La uniformidad en el caso de los números aleatorios, significa que en un rango [a,b] cada intervalo tenga la misma probabilidad de ocurrir. Una distribución 100% uniforme luce de la siguiente forma:
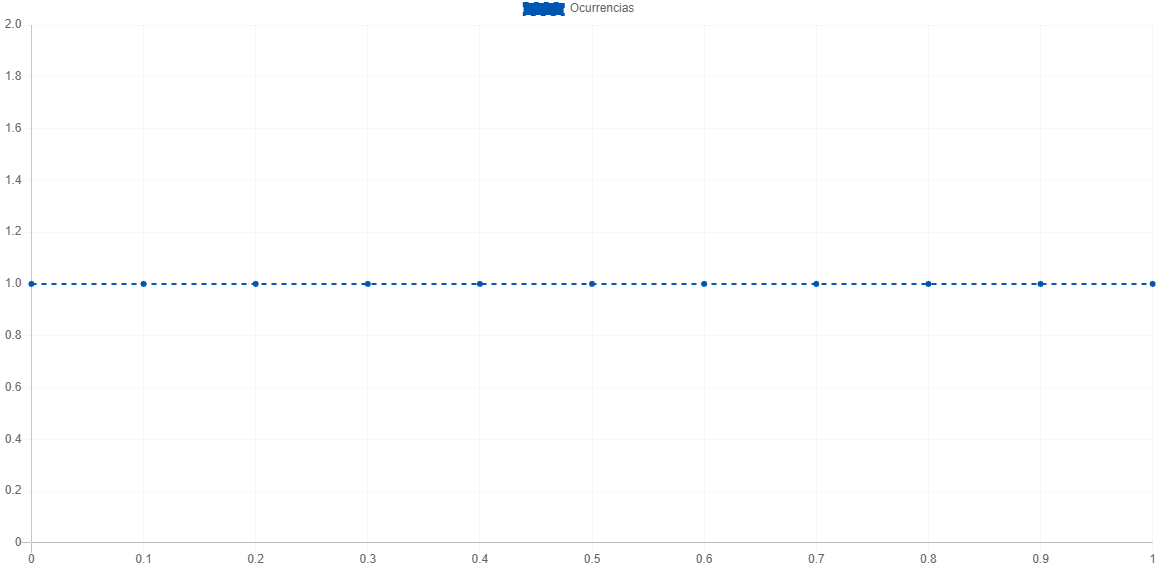 Gráfica completamente uniforme
Gráfica completamente uniforme
Una de las pruebas para determinar este comportamiento es la de chi-cuadrada x2:
$$ {\chi}^2=\sum_{k=1}^{n} \frac{(O_i - E_i)^2}{E_i} $$
Donde:
oi: datos obtenidos
ei: datos esperados
Primero formulamos nuestra hipótesis nula (h0) e hipótesis alternativa (h1).
| Hipótesis | |
|---|---|
| H0 | Los datos son uniformes |
| H1 | Los datos no son uniformes |
Sea 'n' el número de datos que vamos a evaluar, determinamos el número de intervalos que vamos a utilizar de la siguiente manera: √n, por ejemplo:
Si tenemos 100 números, nuestro intervalo va a ser de 10.
Si tenemos 200 será 14.1421 redondeando hacia arriba queda 15.
Los datos obtenidos son los datos que vamos a evaluar. Como lo que estamos evaluando son números aleatorios, esperamos tener una distribución de tipo y = a donde a = [0,1] como en la gráfica mostrada anteriormente. Entonces el número esperado de eventos en una categoría sería, el número de datos a evaluar sobre el número de intervalos.
En caso de tener 100 números será 10 casos esperados en cada categoría.
En caso de tener 200, 13.33.
En caso de tener 300, 16.666.
Para determinar el valor del rango de cada categoría en nuestro caso sería uno sobre el número de intervalos que tenemos. Para determinar las ocurrencias posicionamos nuestros números aleatorios a la categoría que pertenecen. Por ahora si tomamos como muestra esta lista de 300 números nuestro progreso sería el siguiente:
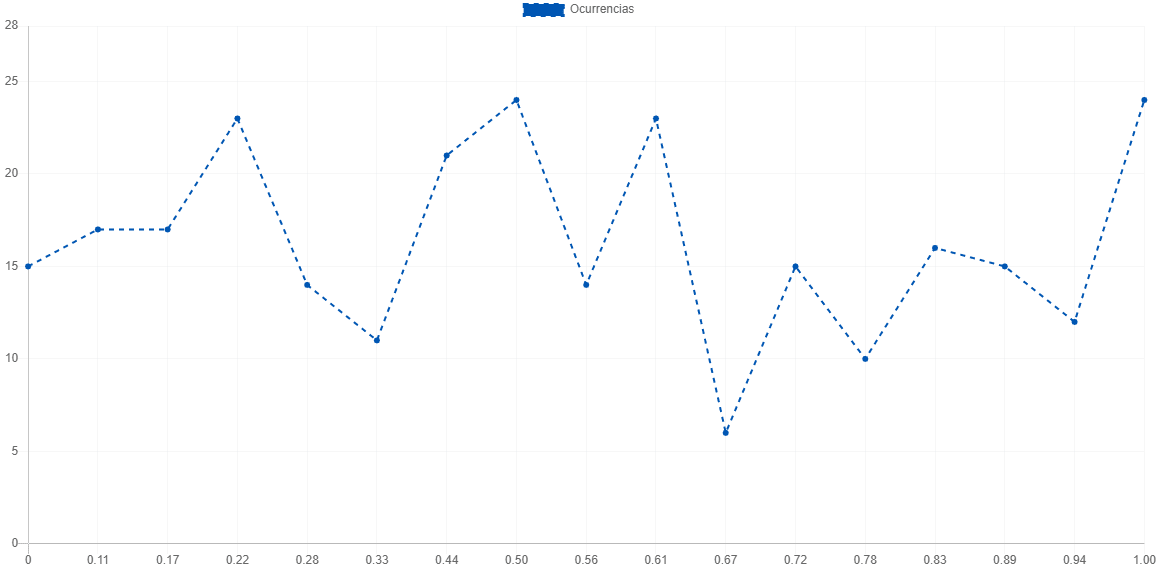
Muestra generada a partir de Math.Random() en la consola de Google Chrome.
Visualmente entre más recta es la línea, más uniforme es. Por lo que a simple vista ya podemos intuir un resultado.
Para corroborar lo que vemos, necesitamos, el valor de chi-cuadrada(x2), los grados de libertad (K) y un nivel de confianza (α).
Al aplicar la fórmula de chi-cuadrada: x2=28.92
Para calcular K = Número de intervalos - 1, en este caso K=17.
El nivel de confianza (α) que usaré es de 0.05, pero puede ser diferente, ya que este es decidido por la persona encargada de la investigación, es el riesgo que se toma.
Se puede calcular de dos formas. En una tabla de probabilidades de chi-cuadrada con el área a la derecha se busca los grados de libertad de 17 y buscamos el valor que más se acerque a nuestro resultado. Nos situamos entre la columna 0.05 y 0.025, esa va a ser nuestra probabilidad, que exactamente es: 0.03527. La multiplicamos por 100: 3.527% y este es el valor de que nuestra hipótesis nula esté correcta. De que nuestros datos sigan una distribución uniforme. Como 5% < 3.527% no se cumple, rechazamos nuestra hipótesis nula y aceptamos la hipótesis alternativa.
Los números no son uniformes como se mira a simple vista en la gráfica.
La otra forma calcularlo es buscando directamente nuestro valor α en la columna correspondiente. Vamos a la intersección k=17,α=0.05=27.587. Si el resultado de nuestra x2 es menor que el resultado de la intersección se acepta la hipótesis nula de lo contrario se rechaza. Como 28.32666 < 27.587 no se cumple, se rechaza la hipótesis nula y se acepta la hipótesis alternativa.
Prueba de independencia
Como lo mencione antes, obtuve rachas de tres o cuatro nombres seguidos. Utilizaré la prueba de rachas ascendentes y descendentes para determinar el número esperado máximo y mínimo de rachas que pueden existir en una secuencia aleatoria. Esto dependiendo de la longitud de los números evaluados.
Para aplicar esta prueba necesitamos de los siguientes estadísticos:
$$ μR=\frac{2n - 1}{3} $$
$$ σ2 R =\frac{16n - 29}{90} $$
$$ Z = \frac{R - μR}{σR} $$
Donde:
R: El número esperado de rachas
n: El número de datos a evaluar
μR: La media de rachas que esperamos tener
σ2R: La varianza del número esperado de rachas
Z: Valor estándar de la distribución normal para la prueba.
Igual que antes establecemos primero nuestra hipótesis nula (h0) e hipótesis alternativa (h1).
| Hipótesis | |
|---|---|
| H0 | Los datos son independientes |
| H1 | Los datos no son independientes |
Clasificamos los números como bien el nombre lo indica. Como racha ascendente o descendente. Ejemplo: Dada la siguiente lista: 0.1, 0.2, 0.3, 0.4, 0.2, 0.3, 0.1, 0.2, 0.3. Vemos que los primeros cuatro números tienen una racha ascendente, intercala 3 números y vuelve a ascender. Como lo siguiente: ↑ ↑ ↑ ↑ ↓ ↑ ↓ ↑ ↑ Tenemos lo siguiente:
| Racha | Longitud |
| 1 | 4 |
| 2 | 1 |
| 3 | 1 |
| 4 | 1 |
| 5 | 2 |
Transpuesta nuestra tabla de tal manera que ahora clasificamos según la longitud de la tabla:
| Longitud de rachas | 1 | 2 | 3 | 4 | Total |
| Número de rachas | 3 | 1 | 0 | 1 | 5 |
Si aplicamos lo que sabemos hasta ahora a la lista de nuestros 300 números iniciales, quedaría de la siguiente manera:
| Longitud de rachas | 1 | 2 | 3 | 4 | Total |
| Número de rachas | 116 | 55 | 19 | 4 | 194 |
Ahora que ya sabemos que son 194 rachas, tenemos lo necesario para calcular los tres estadísticos:
μR = 199.666 El número esperado de rachas
σ2R = 52.01 La varianza
Z = -0.108 El valor de la distribución normal
Para determinar la independencia, buscaríamos ahora en una tabla de distribución normal el valor α/2. Seguiré usando 0.05 de alpha, por lo que buscaré el valor de 0.025. Si vamos a los valores de los laterales encontramos que la desviación normal es de 1.96. Si nuestro valor α fuera 0.1 para tener una confianza del 90% la desviación normal sería de 1.65.
Para saber si aceptamos nuestra hipótesis nula evaluamos si el valor absoluto de nuestra Z es menor a la desviación normal de la tabla. De lo contrario se rechaza.
|-0.108|<1.96 como esto es verdadero, se acepta nuestra hipótesis nula de que las rachas son independientes.
Distribución de la longitud de las rachas
De forma adicional podemos calcular si la longitud de las rachas son adecuadas con la fórmula de chi-cuadrada utilizada anteriormente.
$$ {\chi}^2=\sum_{k=1}^{n} \frac{(O_i - E_i)^2}{E_i} $$
Donde:
oi: datos obtenidos
ei: datos esperados
Lo que cambia es que ahora nuestros números esperados los calcularemos de con la siguiente ecuación.
$$ ei = \frac{2}{(i + 3)!}[n(i^2 + 3i + 1) - (i3 + 3i 2 - i - 4)] $$
Así que retomando nuestros datos de rachas obtenidas tenemos 4 diferentes longitudes de rachas:
| Longitud de rachas | 1 | 2 | 3 | 4 | Total |
| Número de rachas | 116 | 55 | 19 | 4 | 194 |
$$ e1 = \frac{2}{(1 + 3)!}[300(1^2 + 3(2) + 1) - (1^3 + 3(1^2) - 1 - 4)] = 125.083 $$ $$ e2 = \frac{2}{(2 + 3)!}[300(2^2 + 3(2) + 1) - (2^3 + 3(2^2) - 2 - 4)] = 59.766 $$ $$ e3 = \frac{2}{(3 + 3)!}[300(3^2 + 3(3) + 1) - (3^3 + 3(3^2) - 3 - 4)] = 17.369 $$ $$ e4 = \frac{2}{(4 + 3)!}[300(4^2 + 3(4) + 1) - (4^3 + 3(4^2) - 4 - 4)] = 3.768 $$
Lo cual son números similares a los obtenidos.
Existe la restricción de que los números observados y esperados no pueden ser menor que 5. Por lo que e4 se le sumaría a e3 quedando de la siguiente manera:
| Observados | 116 | 55 | 23 |
| Esperados | 125.083 | 59.766 | 21.137 |
Con estos datos calculamos chi-cuadrada (X2) = 1.2038 k = 4-1 = 3 p=0.7521 (valor de la tabla de chi cuadrada)
De igual forma determinamos nuestra hipótesis donde si α < p(1.2038,3), aceptamos nuestra hipótesis nula de lo contrario aceptamos la hipótesis alternativa
Como 0.05 < 0.7521 se acepta la hipótesis nula de que existe independencia en las rachas
Esta muestra nos dio que los números no son uniformes pero sí independientes
Resultados
Test 1
En 100 pruebas de 100 números cada una, se obtuvieron los siguientes resultados:
| Número de pruebas correctas | 1 | 2 | 3 | Total |
| Valores | 11 | 21 | 68 | 100 |
De las 100 pruebas:
68 pruebas cumplieron con la uniformidad, independencia y longitud.
1 Pruebas que no cumplieron la uniformidad e independencia pero sí la longitud de rachas.
6 Pruebas que no cumplieron la uniformidad y longitud pero sí la independencia.
2 Pruebas que cumplieron la uniformidad y la longitud pero no la independencia.
18 Pruebas que cumplieron la uniformidad e independencia pero no la longitud de rachas.
1 Pruebas que no cumplieron la uniformidad pero sí la longitud y la independencia.
4 Pruebas que cumplieron la uniformidad pero no la independencia ni longitud de rachas.
Test 2
En 100 pruebas de 3000 números cada una, se obtuvieron los siguientes resultados:
| Número de pruebas correctas | 1 | 2 | 3 | Total |
| Valores | 3 | 48 | 49 | 100 |
De las 100 pruebas:
49 pruebas cumplieron con la uniformidad, independencia y longitud.
0 Pruebas que no cumplieron la uniformidad e independencia pero sí la longitud de rachas.
2 Pruebas que no cumplieron la uniformidad y longitud pero sí la independencia.
2 Pruebas que cumplieron la uniformidad y la longitud pero no la independencia.
42 Pruebas que cumplieron la uniformidad e independencia pero no la longitud de rachas.
4 Pruebas que no cumplieron la uniformidad pero sí la longitud y la independencia.
1 Pruebas que cumplieron la uniformidad pero no la independencia ni longitud de rachas.
Conclusión
Si recordamos, para que una secuencia de números sea aleatoria, es necesario que tenga distribución uniforme y que sea independiente. Por lo que podríamos decir que los 18 números y 42 números, que no cumplieron la prueba de longitud de rachas, pero sí las de uniformidad e independencia, del test 1 y 2 respectivamente, también se comportan como números aleatorios.
Podríamos decir que para el test 1 de 100 pruebas de 100 números cada una, 86 son aleatorias y de esas 86, 18 no cumplen la longitud de rachas.
Para el test 2 de 100 pruebas de 3000 números cada una, 91 son aleatorias y de esas 91, 42 no cumplen la longitud de rachas.
En cuanto al problema inicial puedo decir que los números en la mayoría de los casos son legítimamente aleatorios, y que es normal que siga viendo nombres que ocurran en rachas seguidas.
¿Tus números son aleatorios?
Puedes probar esta herramienta para evaluar tus números aleatorios. Ya que sabes los procedimientos de las pruebas de números aleatorios, te invito a contribuir en este repositorio donde encontrarás el código que he estado escribiendo al mismo tiempo de escribir este post.
Introduce números que sean entre 0 y 1 separados por espacios, intenta tantos números quieras, entre más números mejor. El Alpha que tomará la prueba es de 0.05.




